파드의 생애주기
개요
파드의 라이프사이클은 복합적이라 꽤나 복잡하다.
사실 엄청 어려울 개념은 아니라고 생각하는데 만든 사람들이 왜 이렇게 만들었는지 조금 궁금하다.
구체적으로는, 왜 이렇게 문서를 썼는지가 궁금하다..
단계(phase)라는 게 있고, 또 한편으로 조건(condition)이라는 것도 있다..
이 관계를 최대한 파악하면서 가보자.
전체 라이프사이클
사용자가, 혹은 워크로드를 통해 파드를 만들어야 하는 요청이 생긴다.
그러면 어느 노드에 파드를 만들 것인가가 첫번째 관건이다. -> 스케줄링
그 이후에는 해당 노드의 kubelet이 파드를 만드는 역할을 담당하며, 아래의 [[#파드 단계(phase)]]를 거치게 된다.
언젠가 종료
스케줄링
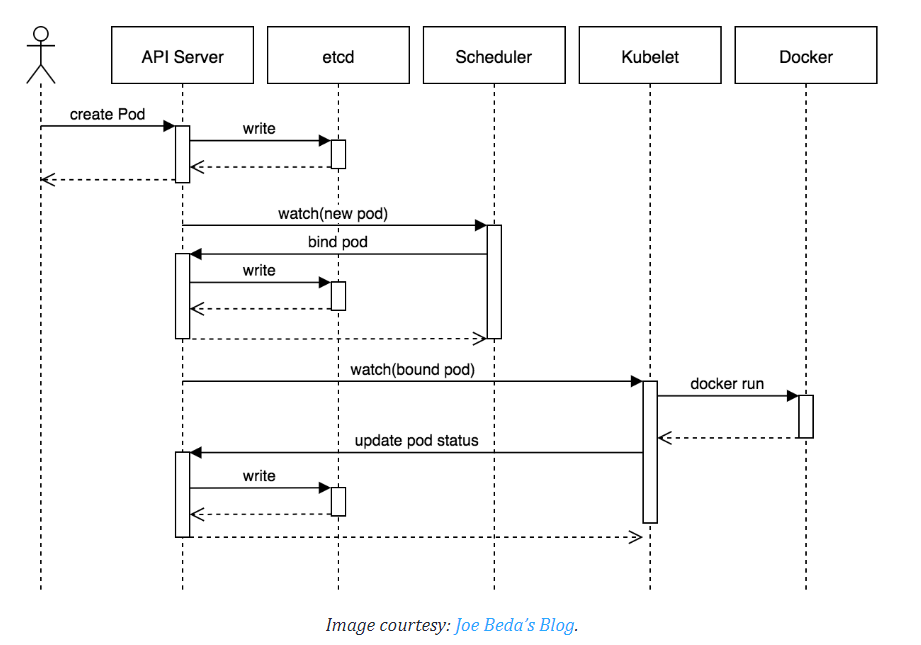
파드를 만드는 것에 대한 요청이 들어오는 것이 당연히 가장 먼저 선행된다.
구체적으로는 etcd에 파드에 대한 정보가 기록되고, 이를 특정 노드의 kubelet이 인지하는 과정이다.
이 과정은 전체 주기에서 한번만 발생한다.
이를 조금 더 세분화하면 이런 과정을 거친다.
- 스케줄링
- kube-scheduler가 어떤 노드에 파드가 들어가야 할지 지정하는 과정
- 적절한 정책에 따라 들어갈 만한 위치의 노드를 특정하면 이를 Etcd에 정보로 기록한다.
- 바인딩
- 파드를 특정한 노드에 할당하는 과정
- 스케줄링이 된 이후, kubelet이 etcd의 정보를 읽어들인 후에 자신 노드에 파드가 생성돼야 한다는 것을 인지하는 과정이다.
- 이후 kubelet은 본격적으로 파드를 생성하는 동작을 실행한다.
과정을 이렇게 세분화하는 이유는 다음의 상황이 존재하기 때문이다.
가령 어떤 노드가 모종의 이유로 파괴되거나 연결이 끊긴다고 생각해보자.
- 파드가 스케줄링되기 이전
- 한 노드가 사용할 수 없는 상태이기에 스케줄러는 다른 노드에 파드를 스케줄링한다.
- 파드가 해당 노드에 스케줄링된 후
- 이미 스케줄링은 완료되었다는 것은 이미 etcd에 정보가 남았다는 뜻
- 이미 해당 노드는 사용 불가이기에 해당 노드의 kubelet이 파드를 만드는 작업이 없다는 것이기도 하다.
- 즉, 쿠버네티스 입장에서 해당 파드는 실행되지 않게 되는 것이다.
- 이 상황에 대해서 쿠버네티스는 파드를 건강하지 않은 상태로 진단하고 파드가 죽었다고 상태를 정의한다.
- 파드는 리소스 부족이나 노드의 파괴로부터 살아남지 못한다.(A Pod won't survive an eviction due to a lack of resources or Node maintenance.)
참고로 1.30 버전부터 pod scheduling readiness라 하여 스케줄링 게이트가 제거될 때까지 파드 스케줄링을 연기하는 전략이 가능하다.
통상적으로 파드가 회복될 수 없는 상태라면 쿠버네티스는 새로운 파드를 만들어버리는 것을 선택한다.
이를 탐지하고 관리하는 작업은 kube-controller-manager가 담당한다.
(새로운 파드를 어디에 할당할지는 또다시 kube-scheduler의 일이 될 것이다.)
반대로 말하면 이 경우 동일한 UID를 가진 파드를 유지할 수는 없다는 것이다.
그래도 이름은 똑같이 할 수 있다!
이를 주의 깊게 여겨야 하는 이유는 스토리지 문제에 있다.
새로 파드가 만들어진다는 것은 이전 파드가 사용하던 볼륨이 유지되지 않는다는 것이다.
따라서 이전 파드에 중요한 정보가 휘발되지 않도록 하는 대책이 요구된다.
파드 단계(phase)
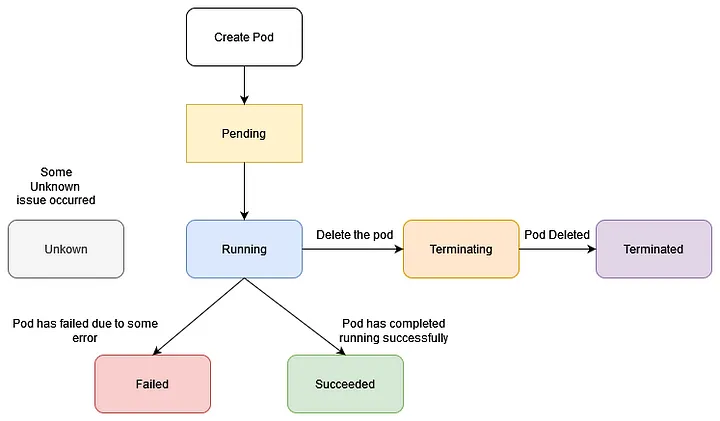
바인딩이 된 이후의 파드는 다음의 단계를 가진다.
이 단계는 매우 단순하고 추상 요약된 상태에 불과하다는 것을 유의해야 한다.
실제로는 각 단계 안에서 다양한 상태를 가질 수 있다.
대신 이 단계로 정의된 상태들은 순서가 불변하고 보장된다.
Running이었던 놈이 Pending으로 돌아가거나 하는 일은 발생하지 않는다는 것이다.
- Pending
- 클러스터 내에 파드가 생성되었다.
- 그러나 내부 컨테이너가 아직 실행할 준비가 안 된 상태이다.
- 가령 컨테이너 이미지를 받고 있는 상황
- pause container만 세워져 있는 상황
- Running
- 파드가 노드에 바인딩됐다.
- 내부에 최소 하나의 컨테이너가 실행 중이거나 시작, 재시작 중이다.
- running이라 해서 무조건 파드가 원하는 대로 움직이는 중이라는 것은 아닐 수도 있다는 것에 유의하자
- 아래 [[#컨테이너 상태]]를 참고하자.
- 초기화 컨테이너가 실행 중일 때 이 단계.
- Succeeded / Failed
- succeeded
- 모든 컨테이너가 성공적으로 종료되었고, 재시작되지 않는다.
- failed
- 최소 하나의 컨테이너가 실패로 종료되었다.
- 종료되면서 0이 아닌 값이 시스템에 반환되었고 자동 재시작이 불가능한 상태이다.
- 컨테이너가 재시작이 불가능한 상태는, 아래에서 더 자세히 보자.
- T-파드가 failed 뜨는 상황이란 사실 많지 않다.
- 보통 노드가 클러스터에서 사라진다면 해당 노드에 위치한 모든 파드는 failed 상태가 된다.
- 이 상태들은 컨테이너 종료 반환값을 토대로 결정된다.
- succeeded
- Unknown
- 모종의 이유로 파드의 상태가 확인되지 않는다.
- 이는 노드 통신이 불안정할 때 주로 발생한다.
Terminating
참고로 파드가 종료되는 중에는 Terminating이라는 상태가 출력된다.
그러나 공식 문서에서는 이것을 페이즈로 치지 않는다.
기본적으로 파드는 안전한 종료 텀으로 30초 동안 이 상태를 유지한다.
이를 깨고 싶다면 종료 조건을 양식에 작성하거나, --force 옵션을 주도록 한다.
자세한 내용은 아래 [[#파드의 종료]]를 참고한다.
컨테이너 상태
파드의 상태와 컨테이너의 상태는 별개이다.
컨테이너의 상태는 파드의 Running 단계에서 이뤄지는 상태라고 보면 될 듯하다.
kubelet이 Container Runtime을 통해 파드를 만드는 과정 속에서, 컨테이너는 다음의 세 가지 상태를 가진다.
- Waiting
- 다른 상태가 아니라면, 컨테이너는 기본적으로 이 상태이다.
- 컨테이너는 running 상태가 되기 위해 필요한 각종 작업을 진행하고 있다.
- 가령 컨테이너 이미지를 받고 있거나, Secret 데이터를 적용하고 있는 상태
- Running
- 컨테이너가 이슈 없이 실행되고 있는 상태
postStart훅은 이 상태 이전에 완료됨
- Terminated
- 컨테이너가 성공적이든, 실패했든 종료 작업을 실행하는 상태
preStop훅이 이 상태 이전에 작동
container lifecycle hooks를 통해 컨테이너 상태에 따른 각종 작업을 진행하거나 디버깅을 할 수 있다.
위의 postStart, preStop이 이 내용에 해당한다.
파드 상태(condition)
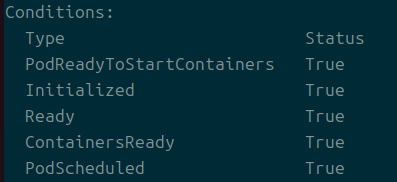
아무튼 파드의 현재 상태를 나타내는 또 하나의 지표라고 보면 된다.
마찬가지로 describe를 통해 관측할 수 있다.
다음의 상태가 존재한다.
- PodScheduled
- 노드에 스케줄됨
- PodReadyToStartContainers
- 파드 샌드박스가 만들어지고 네트워크 설정이 완료됨
- 베타 버전
- ContainerReady
- 파드 내부의 모든 컨테이너가 준비됨
- Initialized
- 초기화 컨테이너가 성공적으로 실행됨
- Ready
- 파드가 요청을 처리할 준비가 되어 매칭되는 서비스의 로드 밸런싱 풀에 등록돼야 함
- 컨테이너 프로브 설정을 통해 커스터마이징할 수 있는 요소
위의 값들이 True, False, Unknown의 상태로 나타날 수 있다.
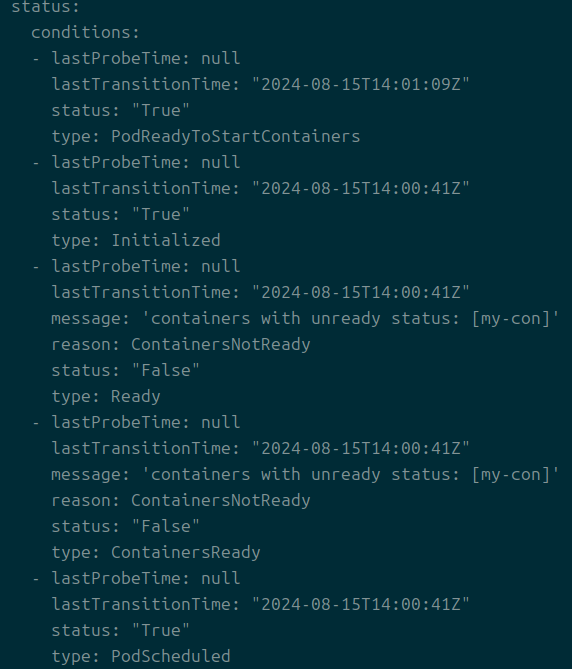
무언가 실패하는 상태일 때는 yaml 파일로 현재 상태를 뽑아서 message라는 값을 통해 마지막 상태의 이유를 파악할 수도 있으니 참고.
어차피 logs나 describe로 확인할 수 있어서 이렇게 볼 일은 거의 없을 것이다.
Pod Readiness Gate
이건 로드밸런서와 관련된 상태이다.
spec:
readinessGates:
- conditionType: "www.example.com/feature-1"
이런 식으로 파드 스펙에 readinessGates라는 필드를 작성하면 파드 상태에 해당 타입이 추가된다.
이걸 언제 사용하는가?[1]
우리는 컨테이너의 상태를 체크하기 위해 레디네스 프로브를 사용하지만, 클러스터 외부에서 이를 활용하는 것이 녹록치 않은 경우가 종종 있다.
가령 파드들을 여러 개 새로 띄우거나 삭제하는 업데이트 과정이 있다고 쳐보자.
클러스터 내부에서는 이것이 빠르게 반영이 되어도 AWS LB에서 타겟 그룹을 업데이트하는 속도는 그보다 느리다.
외부 로드 밸런서는 헬스체크 상 해당 백엔드가 괜찮다고 판단하고 있는 시점에 사실 파드는 준비가 되지 않았다던가, 이런 짧은 간극이 발생할 수 있으며, 이는 서비스 장애로 이어질 가능성이 높다는 것이다.
그래서 세팅을 하는 것이 바로 레디네스 게이트이다.
여기에서 다루지는 않겠으나, 이 설정을 커스텀 해주면 이 값은 외부 로드밸런서의 헬스체크가 성공했을 때 True가 된다.
그리고 이게 세팅되면 위의 Ready라는 상태는 레디네스(Readiness)까지 충족돼야 True가 된다.
그래서 외부의 로드 밸런서가 트래픽을 정말 전달할 수 있는 상태일 때만 파드에 트래픽이 실제로 흘러갈 수 있도록 동기화를 해줄 수 있는 것이다.
이 파드가 클러스터 외부 환경에서까지 구동될 준비가 되었다를 나타내는 지표라고 보면 될 것 같다.
E-레디네스 프로브와 레디네스 게이트
전자에 대해서는 컨테이너 프로브쪽에서 다루는 것으로 하고 후자를 조금 더 본다.

이런 식으로 스펙에 명시를 하면, 파드의 상태의 키로 들어가게 된다.
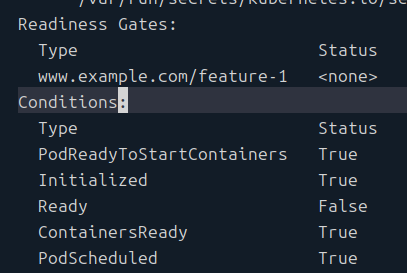
그래서 describe로 또 볼 수 있게 된다.
기본적으로는 False로 설정된다고 하나 내 경우에는 그렇지 않았다.
파드 네트워크 레디네스
참고로 이전 개발 과정 상에서는 PodHasNetwork라고 불렸다고 한다.
파드가 노드에 스케줄된 후 파드는 kubelet에 의해 승인되며 필요한 스토리지 볼륨이 마운트 된다.
이 단계가 끝난 후에 kubelet은 파드의 네트워크와 런타임 샌드박스 설정을 위해서 Container Runtime과 협업한다.
만약 PodReadyToStartContainersCondition feature gate가 활성화됐다면, 이 컨디션은 파드의 컨디션으로 자동 추가된다(참고로 Kubernetes v1.31 - Elli부터는 기본이 활성화).
다음의 경우에 kubelet은 PodReadyToStartContainers 컨디션을 거짓으로 만든다.
- 파드의 생애주기 초반, 아직 kubelet이 컨테이너 런타임으로 샌드박스를 세팅하지 않았을 때
- 파드의 생애주기 이후, 파드의 샌드박스가 부숴졌을 때
- 파드의 퇴출(evict) 없이 노드가 재부팅되는 경우
- 가상 머신의 상황에서 컨테이너 네트워크 설정을 초기화하기 위해 샌드박스 리부팅이 필요한 경우
당연히 이 경우가 아니라면 이 컨디션은 참이 된다.
이 값이 참이어야만 kubelet은 컨테이너 이미지를 받고, 컨테이너를 만드는 행위를 하게 된다.
init container가 있을 때와 없을 때 상황이 조금 다르다.
있다면 kubelet은 위 과정을 완료한 이후 초기화 컨테이너까지 완료됐는지 확인한 후에야 Initialzed 조건을 참으로 바꾼다.
없다면 Initialized 조건은 샌드박스 생성, 네트워크 설정 이전에 참으로 설정된다.
파드의 종료
할 일을 마쳤거나, 종료 시그널이 들어온 파드에서는 어떤 일이 발생할까?
파드는 클러스터에서 돌아가는 프로세스이기에 필요 없어졌다고 무작정 KILL 시그널을 날리기보다는 안정적으로 종료되는 것이 바람직하다.
가령 데이터를 안전하게, 아니면 요청을 완전히 수행하고 종료되는 것이 좋다는 것이다.
그래서 종료에 조금 특별한 기능들이 들어가 있는데, 바로 우아한 종료(graceful shutdown)를 지원하는 것이다.
파드는 일정 기간(기본 30초) 동안 안정적인 종료 기간을 두고, 그때까지 종료가 완료되지 않을 경우 강제 종료가 진행된다.
gracful shutdown
이 기간을 유예 기간이라고도 부른다.
기본적으로 우아한 종료 시기에 kubelet은 Container Runtime에 파드 속 컨테이너를 중지하도록 요청을 날린다.
그러면 컨테이너의 메인 프로세스에 TERM 시그널이 날아가게 된다.
이건 프로세스에게 선택권을 넘겨주는 것이기에 종료는 비동기적이고, 정말 종료된다는 보장은 없다.
참고로 만약 이미지에 STOPSIGNAL이 있다면 이것을 TERM 대신 날리게 된다.
또 참고로 이 시기에 kubelet 등의 관리 서비스가 다시 시작되면, 클러스터에서는 전체 원래 유예 기간을 포함해 처음부터 다시 시도한다.
force shutdown
그러다 종료 시기가 지나면, KILL 시그널이 날아가게 되며 파드는 kube-apiserver에서 지워진다.